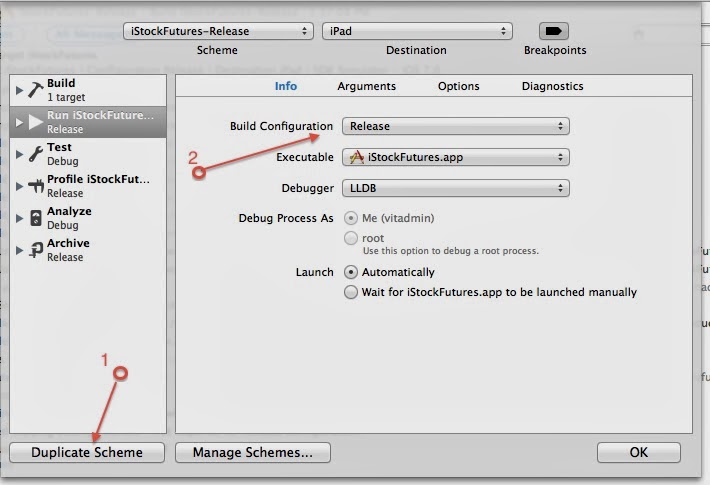
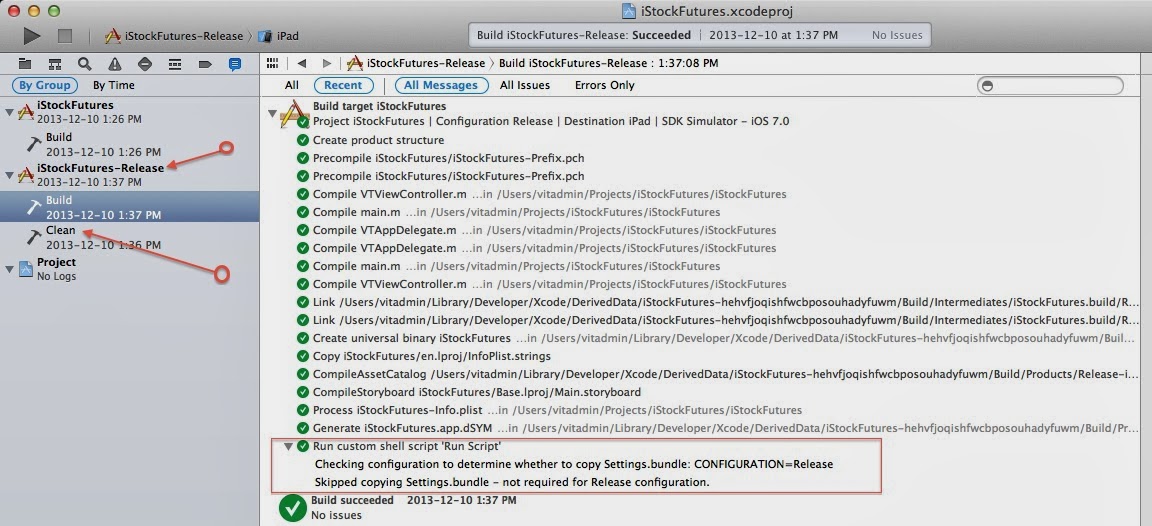
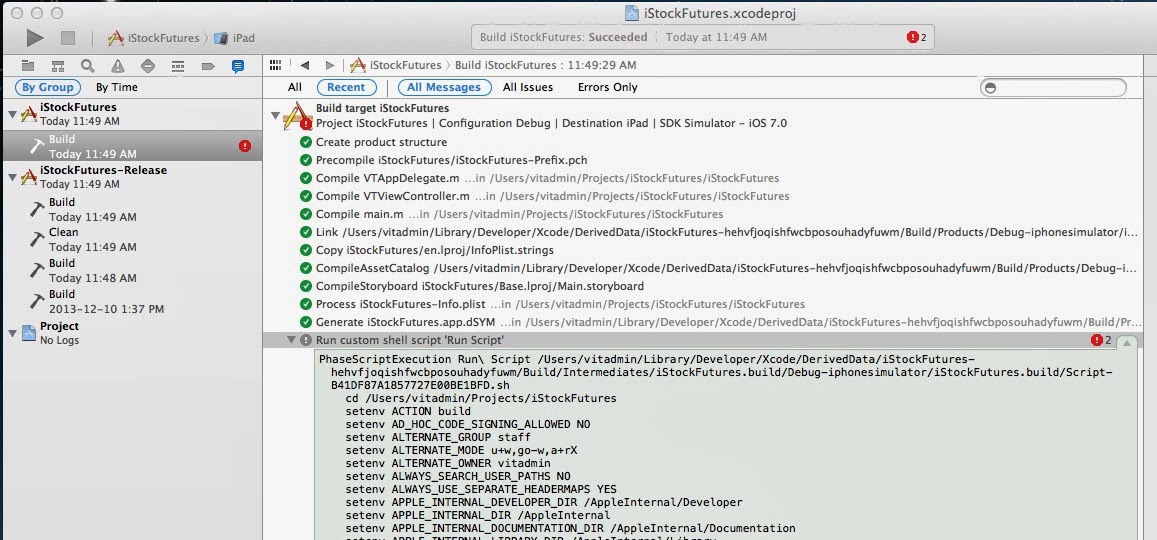
After adding the second servlet and a servlet mapping to the web.xml configuration of a Spring-based web application, a JUnit test that relied on the Spring MVC Test framework started to fail.
The unit test was used to verify proper functioning of controller security layer that is based on Spring Security framework (v3.2.9 at the time).
The JUnit code (fragments):
@ContextConfiguration(loader = WebContextLoader.class, locations = {
"classpath:spring/application-context.xml",
"classpath:spring/servlet-context.xml",
"classpath:spring/application-security.xml"})
public class AuthenticationIntegrationTest extends AbstractTransactionalJUnit4SpringContextTests {
@Autowired
private WebApplicationContext restApplicationContext;
@Autowired
private FilterChainProxy springSecurityFilterChain;
private MockMvc mockMvc;
...
public void setUp() {
mockMvc = MockMvcBuilders.webAppContextSetup(restApplicationContext)
.addFilter(springSecurityFilterChain, "/*")
.build();
}
@Test
public void testCorrectUsernamePassword() throws Exception {
String username = "vitali@vtesc.ca";
String password = "password";
ResultActions actions = mockMvc.perform(post("/user/register").header("Authorization", createBasicAuthenticationCredentials(username, password)));
}
}
The test started to fail with the AuthenticationCredentialsNotFoundException as the root cause.
The change that caused the failure was introduced in order to split request security filtering into 2 distinct filter chains. The existing configuration for securing RESTful calls with Basic authentication needed to be amended to add a separate handling of requests supporting the Web user interface of the application.
That necessitated adding a second <security:http> configuration to the application-security.xml context:
<!-- REST -->
<http pattern="/rest/**" entry-point-ref="basicAuthEntryPoint" authentication-manager-ref="restAuthManager">
...
</http>
<http pattern="/web/**" entry-point-ref="preAuthEntryPoint" authentication-manager-ref="webAuthManager">
<custom-filter position="PRE_AUTH_FILTER" ref="preAuthFilter" />
<!-- Must be disabled in order for the webAccessDeniedHandler be invoked by Spring Security -->
<anonymous enabled="false"/>
<access-denied-handler ref="webAccessDeniedHandler"/>
</http>
That is what ultimately caused the test to fail since the JUnit was not using Servlet path.
It is important to note that Spring MVC Test Framework runs outside of a web container and has neither dependency nor is using the web.xml.
When testing with MockMvc, it is not required to specify the context path or Servlet path when submitting requests to the controllers under test.
For example, when testing this controller:
@RequestMapping(value = "/user/register", method = RequestMethod.POST, headers = "accept=application/json,text/*", produces = "application/json")
@PreAuthorize("hasPermission(null, 'ROLE_USER')")
@ResponseBody
public RegistrationResponse register(@RequestBody(required=false) UserDeviceLog userDeviceLog) {
...
it would be sufficient to send request only specifying the mapping:
mockMvc.perform(post("/user/register").header("Authorization", createBasicAuthenticationCredentials(username, password)))
Resolution:
1. Specify a correct Servlet path in the request URL and also add the mapping by passing the path to the servletPath(String) method of the MockHttpServletRequestBuilder class:
mockMvc.perform(post("/rest/user/register").servletPath("/rest").header("Authorization", createBasicAuthenticationCredentials(username, password)));
2. Configure the MockMvc instance with the security filter mapping that matches the pattern specified in the application-security.xml configuration:
@Before
public void setUp() {
mockMvc = MockMvcBuilders.webAppContextSetup(restApplicationContext)
.addFilter(springSecurityFilterChain, "/rest/*")
.build();
}